2023년도 겨울학기 과학계산 트레이닝 세션의 세 번째 주제는 인공신경망을 이용한 뇌인지 기능의 모델링 입니다.
이번 학기의 과학계산 트레이닝 세션은 다양한 주제를 이것 저것 배워 보는 것을 지향하고 있지만,
그래도 저와 같이 인지신경과학을 연구하고 있는 분들에게 직접적으로 도움이 될 수 있는 프로젝트도 시도해 보면 좋을것 같아 이러한 주제로 결정하게 되었습니다.
컴퓨터를 이용하여 뇌에서 일어나는 mental process를 모델링한다는 것은 실제 과학계산이 추구하고 있는 바와도 굉장히 일치한다고 볼 수 있구요.
다만 안타까운 점은 이 프로젝트에 등장하는 몇몇 용어들은 한국어로 잘 번역해서 의미를 전달하기가 쉽지 않아서… 글이 다소 예쁘진 않겠지만 좀 혼용해서 쓰도록 하겠습니다. 너그러운 양해 부탁드립니다.
Psychological function 혹은 mental process를 모델링 하는 데엔 여러가지 방법이 있습니다.
Baysian framework를 이용한 방법이 널리 사용되고 있고, symbolic system의 관점에서 접근 하는 방법도 있습니다.
이와 더불어 최근에는 신경망 모델을 이용한 접근이 적극적으로 도입되고 있는데요.
특히 순환신경망(RNN)의 경우 시간적인 흐름을 가진 정보(sequential information)를 처리하는데 적합한 특성을 가지고 있어
다양한 인지 과제를 수행하며 발생하는 mental proccess를 모델링 하기에 적합하다고 알려져 있습니다.
RNN의 신경망 유닛들은 재귀적인 연결 구조(recurrent connection)를 가져 각 신경망 유닛이 표상하고 있는 은닉 상태(hidden state)를
유지하거나 업데이트 할 수 있습니다. 이를 통해 RNN은 과거의 정보를 활용하여 의사 결정 과정을 수행 할 수 있게 됩니다.
이렇게 sequential information을 처리 할 수 있는 RNN은 임의의 동역학 계(dynamical system)를 모델링 하는데 있어 유용한 점이 많다고 볼 수 있겠습니다.
학습 목표
이번 주차의 학습 목표는 다음과 같습니다.
- 인지 과제를 모델링 하기 위해 컴퓨터가 이해할 수 있는 형태로 추상화 합니다.
- 파이썬 기반의 딥러닝 프레임워크인
PyTorch를 이용하여 RNN 모델을 구현합니다.
- 인지 과제를 수행하는 동안 RNN 모델의 행동 데이터를 분석하고 동물의 행동 데이터와 비교 합니다.
이번 프로젝트는 여러 주차에 걸쳐 진행 될 예정인데요.
첫 시간에는 인지 과제를 구현하고, RNN 모델을 학습시키고, 행동 데이터를 분석하여 동물의 행동 데이터와 비교하는 것이 목표입니다.
다음 주차에는 RNN 모델 내부에서 일어나는 state dynamics를 분석해 보도록 하겠습니다.
모든 목표가 빠짐 없이 중요한 것은 분명하나, 제가 이번 주차에서 특히 강조하고 싶은 내용은 RNN 모델의 구현 보다는 인지 과제를 적절한 수준에서 추상화 하는 것 입니다.
최근엔 RNN 모델을 직접 구현하지 않더라도 mental process를 모델링 하기 위한 고수준(High-level)의 라이브러리가 다양하게 제공되고 있습니다.
예를 들어 프린스턴 대학교의 신경과학연구소에서 제작한 PsyNeuLink, 예일 대학교의 John D. Murray 연구 팀이 제작한 PsychRNN,
Manuel Molano와 Guangyu Robert Yang 등이 제작한 NeuroGym 등의 라이브러리가 널리 사용되고 있는데요.
여러분이 인지 과제의 추상화와 모델을 분석하는 것을 연습하게 되면 RNN 모델을 구현하는 것 자체는 예시와 같은 고수준의 라이브러리를 사용해서 쉽게 제작 할 수 있습니다.
물론 이 프로젝트에서는 고수준의 라이브러리를 사용하지 않고 직접 구현을 해 보겠지만, 너무 프로그래밍 자체를 겁내지 마시고 프로젝트의 목적과 흐름이 잘 전달 되기를 바랍니다.
문제를 정의하기
모든 문제 풀이의 시작은 풀고자 하는 문제를 잘 정의하는 것 입니다. 모델링 하고자 하는 인지 과제는 목표에 따라 다양한 인지 과정을 포함 할 수 있습니다.
저는 Chandramouli Chandrasekaran et al. (2017) 에서 제안된 시각 판별(Visual discrimination) 과제를 구현 해 보도록 하겠습니다.
해당 과제는 다음 두 가지의 지각 및 인지 과정을 포함하고 있습니다.
- 제시된 시각 자극의 색을 판단하는 시지각 기제
- 각 시행에서 제시되는 시각 단서(visual cue)에 따라 서로 다른 응답을 수행하는 의사 결정(decison making) 기제
시각 판별 과제 (Chandrasekaran et al., 2017)
 Figure 1. 짧은 꼬리 원숭이가 수행하는 시각 판별 과제. Chandramouli Chandrasekaran et al. (2017)
Figure 1. 짧은 꼬리 원숭이가 수행하는 시각 판별 과제. Chandramouli Chandrasekaran et al. (2017)
Chandramouli Chandrasekaran et al. (2017)에서 짧은 꼬리 원숭이를 대상으로 훈련시킨 시각 판별 과제는
과제가 시작된 후 250-400ms 사이에 화면 가운데에 흰색 원반이 주어집니다. 이후 400-900ms 사이에 왼쪽과 오른쪽에 타겟 색이 등장합니다.
타겟 색은 각각 빨간색 혹은 초록색이며, 위치는 서로 바뀔 수 있습니다. 이후 가운데에 빨간색과 초록색 패치가 섞인 체커보드 자극이 등장합니다.
짧은 꼬리 원숭이는 주어진 체커보드에서 우세한 색이 무엇인지 판단하여 가운데 주어진 흰색 원반을 해당 색 쪽으로 가져갑니다(Figure 1B).
체커보드의 Color coherence를 조정하여 과제의 난이도를 조절 할 수 있습니다(Figure 1C).
이 과제는 굉장히 단순하지만 주어진 시각 정보(체커보드의 색과 타겟의 위치)를 연합하여 Motor response로 변환해야 하는 동물 뇌의 핵심적인 인지 기능을 포함하고 있습니다.
여기에 여러분이 타겟 위치가 잠깐 주어지고 마는 제약 조건을 추가한다면 작업 기억(working memory)이라는 또 다른 핵심적인 인지기능을 필요로 하는 과제를 디자인 할 수도 있습니다.
과제를 조금씩 바꾸거나, 새로운 요소를 추가하는 것은 그렇게 어렵지 않으므로 이는 2부에서 더 자세하게 진행해 보도록 하고,
이번 주차에는 이 시각 판별 과제를 수행하는 인공신경망을 구현하고, 순환신경망이 어떻게 시각 정보를 연합하여 Motor response로 변환할 수 있는지 알아보도록 하겠습니다.
과제 구현하기
이 글을 보고 계시는 신경과학 혹은 실험심리학 연구자들은 대부분 PsychToolBox, PsychoPy 등의 소프트웨어를 이용하여 실험 코드를 구현해 본 경험이 있을 것입니다.
인공신경망을 대상으로 하는 연구도 마찬가지 입니다. 첫 과정은 내가 의도한 실험을 정확하게 구현하는 실험 코드를 짜는 것 입니다.
여기서 의도에 맞게 정확하게 구현하는 것 만큼 중요한 것은 적절하게 추상화하는 것인데요.
ㅎㅎ 정확하게 구현해야 하는 요소에 추상화가 필요하다는 이야기는 얼핏 모순적으로 들리기도 합니다.
하지만 동물을 대상으로 하는 실험이든, 인공신경망을 대상으로 한 실험이든 추상화는 정말로 중요합니다.
여러분은 이미 연구의 거의 모든 과정에서 연구의 대상을 목적에 부합하는 한계까지 추상화하는데 잘 훈련되어 있을 거라고 생각 합니다.
다만 인공신경망을 대상으로 한 실험에서는 대부분 인간을 포함한 동물을 대상으로 하는 수준 보다 더 높은 수준의 추상화가 필요하다는 말씀을 드리고 싶습니다.
이는 인공신경망이란 모델 시스템이 가진 근본적인 한계이자 모델 시스템을 이용한 연구의 한계이기도 합니다.
한계라고 하는것 보다는 관심이 되는 연구의 대상이 아니라고 말씀 드리는 것이 조금 더 정확할 것 같네요.
말씀 드린대로 모델 시스템을 구현하는 데에는 여러 수준의 추상화가 가능합니다.
예를 들어 여러분은 인공신경망에게 이 시각 판별 과제에서 제시되는 정보들을 시각 정보에 기반하여 제공 할 수 있습니다.
이 경우엔 인공신경망이 과제를 수행하기 위해서 “빨간색” 혹은 “초록색” 등과 같은 시각 요소들을 처리하기 위한 인지 기능이 필요합니다.
이에 여러분은 우리가 만든 신경망의 입력 레이어를 이미지 기반의 정보 처리에 효과적이라고 알려진 합성곱 신경망(convolutional neural network)을 사용 해 볼 수 있겠습니다.
또한 인공신경망의 출력이 단순히 타겟의 방향이 왼쪽인지 오른쪽인지 이진 분류(binary classification)를 수행하는 것이 아니라
인공신경망 스스로 연결된 로봇 팔을 제어하게 하여 실제로 화면에 제시되는 흰색 원반을 왼쪽 혹은 오른쪽으로 옮기는 운동 기능을 구현 할 수도 있습니다.
뿐만 아닙니다, 여러분들은 로봇 팔을 넘어서 양안 카메라와 팔 다리 로봇 관절이 포함된 로봇 원숭이를 만들 수도 있고,
더 나아가 인공신경망의 유닛들이 더욱 실제 뇌의 신경세포와 유사하게 동작 하게끔 여러 신경생리학적 관찰 결과에 기반한 제약 조건을 추가 할 수도 있습니다.
여러분들이 여기서 “에이 무슨 로봇 팔까지 필요해…” 라고 생각 하셨다면 아마 그 보다는 높은 수준의 추상화가 여러분이 관심이 있는 연구의 대상일 것입니다.
실제로 이와 비슷한 시각 판별 과제를 수행하는 모델 시스템을 고안하며 로봇 팔을 제어하는 것을 연구의 대상으로 포함시킨 연구(J. A. Michaels et al., 2020)도 존재합니다.
이 연구의 경우 운동 신경계의 Grasping neural circuit에 대해 연구했기 때문에 로봇 팔을 제어하는 것 또한 관심이 되는 연구 대상이 될 수 있는 것입니다.
물론 이 글을 읽으시는 대다수의 분들은 분명하게 로봇 팔을 제어하는데에 관심이 없을거라고 생각 하지만, 이는 사실 과학 연구에서 오래된, 쉽게 결론을 내기 어려운 문제 중 하나라고 생각 합니다.
높은 수준의 추상화를 통해 여러분은 모델 시스템을 구현하고 분석하는데 큰 이점을 얻을 수 있지만 이는 반드시 시스템의 경계 조건을 의도치 않게 바꾸게 됩니다.
의도하지 않은 경계 조건의 변화는 그 정도에 따라 여러분이 구하고자 하는 시스템의 해를 바꿀 수 있습니다.
예를 들어 물리학에서 사랑하는 강체(rigid body)는 잘 추상화된 모델 시스템이지만 실세계 문제에서 강체를 가정할 경우 정말 셀 수 없이 많은 심각한 오류를 도출하게 됩니다.
이에 실제 응용역학에서 가정해야 하는 모델 시스템은 더 낮은 추상화 수준을 가져야 할 것입니다.
이 시각 판별 과제의 경우에서도 단순히 이진 분류를 수행하는 인공신경망과 로봇 팔을 제어해야 하는 인공신경망은 결과적으로 왼쪽 혹은 오른쪽을 판별하는 출력 자체는 같더라도 결과를 도출하기 위한 내부 로직과 계산 체계는 완전히 다를 것입니다.
특히 모델 시스템에서 컴퓨터 계산을 통해 얻는 해들은 그 정확도나 정밀도, 그에 따른 오차 등이 여러분들이 자연에서 훈련된 직관을 이용하여 쉽게 발견하기 어려운 경우가 있을 수 있습니다.
그래서 내 연구의 목적과 관심이 되는 연구의 대상이 무엇인지 명확하게 정의하고, 내가 설정한 추상화에 의해 모델 시스템의 경계 조건이 의도하지 않게 바뀌지 않았는지 고려하는 것이 정말 중요하다는 점을 다시 한번 강조 드리고 싶네요.
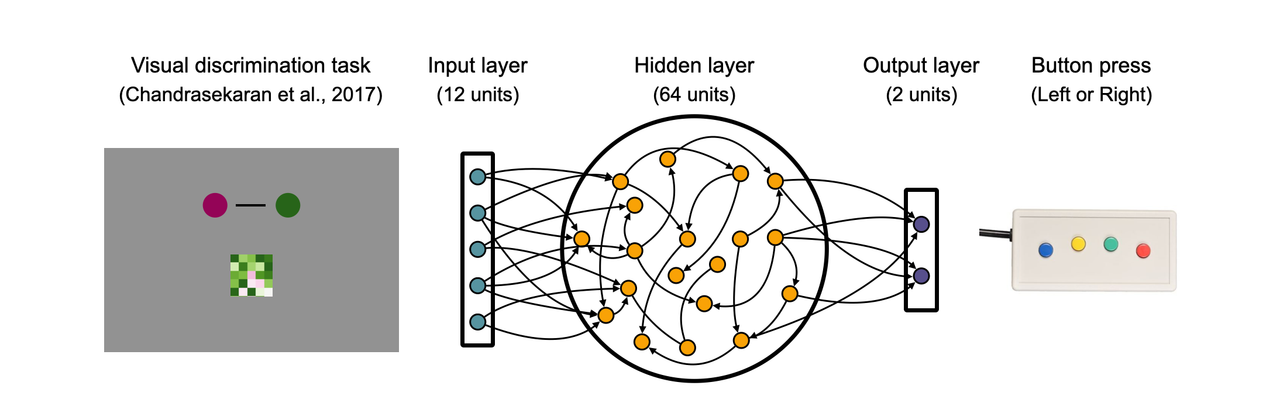 Figure 2. Task overview
Figure 2. Task overview
이번 프로젝트에서는 위 시각 판별 과제를 다음과 같이 추상화 하였습니다.
과제에서 등장하는 시각 정보를 이미지 형태로 입력으로 받지 않고, 적절한 수준에서 추상화하여 12개의 원소를 갖는 벡터로 변환합니다.
64개의 unit을 가진 RNN의 hidden layer를 지나서 RNN 모델은 왼쪽 혹은 오른쪽에 해당하는 버튼을 눌러 응답합니다.
Figure 2의 예시에서 체커보드 패치의 색이 초록색이기 때문에, 주어진 시행의 규칙에 따라 모델은 오른쪽에 해당하는 버튼을 눌러야 합니다.
이제 이렇게 추상화한 과제를 직접 구현해 보겠습니다.
모델의 입력과 출력
먼저 RNN 모델은 각 시행에서 매 시각 $t$에서 길이가 12인 벡터를 입력으로 받습니다.
해당 입력 벡터(Input sequence)의 원소 중 처음 두 원소는 이번 시행의 타겟 위치를 나타냅니다.
이 과제는 왼쪽과 오른쪽 원반이 각각 빨간색, 초록색인 시행과 그 반대인 왼쪽과 오른쪽이 각각 초록색과 빨간색인 두 가지 타입의 시행이 있습니다.
요컨대 첫 번째 타입의 시행일 경우 첫 번째 원소가 1이 되고, 두 번째 타입의 시행일 경우 두 번째 원소가 1이 된다고 보시면 될것 같습니다.
이렇게 현재 타겟이 무엇인지 알려주는 시각 단서는 실험 시작 후 특정 구간 내에서 랜덤하게 등장하게 됩니다.
아래 Task diagram에서 타겟의 시각 단서가 주어지는 시점이 첫 번째 검은색 화살표로 표기되어 있습니다.
 Figure 3. Color coherence가 높은 시각 판별 과제의 예시
Figure 3. Color coherence가 높은 시각 판별 과제의 예시
나머지 10개의 원소는 주어지는 주어진 체커보드의 색을 타나냅니다. 체커보드는 정의된 coherence에 따라 체커보드에 존재하는 패치의 색 분포가 달라지게 됩니다(Figure 1C).
Dominant color가 무엇인지 나오기 전 까지는 완전히 랜덤한 패치가 주어지며, 마찬가지로 실험 시작 후 특정 구간 내에서 랜덤한 시점에
Dominant color에 따라 패치의 색이 변하게 됩니다. 하지만 coherence level이 매우 낮은 경우, 앞선 랜덤 패치와 쉽게 구분이 되지 않을 것입니다.
모델은 이러한 벡터를 입력으로 받아 출력으로 두 개의 버튼을 누르게 됩니다.
모델은 화면에 제시된 Dominant color가 무엇인지 판별하고, 앞서 제시된 타겟의 시각 단서에 따라 해당하는 버튼을 누릅니다.
예를 들어 Figure 3의 경우 이번 시행은 색이 초록색이라 판단 될 경우 왼쪽 버튼을 누르는 시행이며,
이후 높은 coherence level을 가진 초록색 체커보드가 등장하게 됩니다. 이에 모델은 왼쪽 버튼을 누르도록 학습합니다.
 Figure 4. Color coherence가 낮은 시각 판별 과제의 예시
Figure 4. Color coherence가 낮은 시각 판별 과제의 예시
색의 Coherence level이 낮은 시행의 경우 모델이 받는 입력 벡터는 위 예시와 같습니다.
이번 시행의 규칙은 색이 빨간색이라고 판단 될 경우 왼쪽 버튼을 누르는 시행이지만 이후 제시되는 패치의 색이 무엇인지 분명하게 알기 어려운 시행입니다.
시행의 규칙에 따라 모델은 왼쪽 버튼을 누르도록 학습합니다.
데이터셋 정의
이번 프로젝트에서 과제를 구현하기 위해선 널리 쓰이는 딥러닝 프레이워크인 PyTorch의 torch.utils.data.Dataset클래스를 활용해 보겠습니다.
객체 지향 프로그래밍에서 클래스 상속(inheritance)은 부모 클래스(parent class 혹은 super class)로부터
메서드와 속성을 물려받는 것을 의미합니다. 이름과 기능이 너무 직관적이어서 깜짝 놀라셨죠? 😃😃😃 여러분은 이러한 클래스 상속을 이용하여
부모 클래스가 가진 대부분의 기능(메서드와 속성)을 가졌지만 여러분들의 목적에 맞게 살짝 변형된 자식 클래스(child class 혹은 subclass)를 만들 수 있습니다.
아래 VisualDiscrimination 클래스가 Dataset 클래스를 상속 받는 것을 확인 할 수 있습니다.
처음 겨울학기 과학계산 트레이닝 세션을 시작 할 때 말씀 드렸다 시피,
데이터 분석 및 과학계산을 목적으로 프로그래밍을 하시는 분들은 습관적으로 그리고 경험적으로
객체를 사용하지 않는 절차적 프로그래밍(Procedural Programming, PP)을 하시는 경우가 많습니다.
절차적 프로그래밍은 그 나름대로 장점이 많지만, 저는 여러분들이 이번 기회에 데이터와 메서드를 묶은 객체(object)를 중심으로 한 프로그래밍을 연습해 보셨으면 좋겠습니다.
그래사 일부러 더 여러분들에게 익숙하지 않을 수 있는 객체 지향 프로그래밍을 사용하고 있는데요, 계속 하시다 보면 또 익숙해 질 겁니다!
import torch
from torch.utils.data import Dataset
import numpy as np
class VisualDiscrimination(Dataset):
def __init__(self, task_dict):
self.target_dim = task_dict['target_dim'] # Red and Green
self.color_dim = task_dict['color_dim']
self.output_dim = task_dict['output_dim'] # Left and Right
self.target_onset_range = task_dict['target_onset_range']
self.decision_onset_range = task_dict['decision_onset_range']
self.coherence_range = task_dict['coherence_range']
self.trial_length = task_dict['trial_length']
assert np.max(self.decision_onset_range) < self.trial_length
def __getitem__(self, idx):
target_onset = np.random.randint(self.target_onset_range[0], self.target_onset_range[1])
decision_onset = np.random.randint(self.decision_onset_range[0], self.decision_onset_range[1])
coherence = np.random.uniform(low=self.coherence_range[0], high=self.coherence_range[1])
input_seq = np.zeros((self.trial_length, self.target_dim+self.color_dim))
output_seq = np.zeros((self.trial_length, self.output_dim))
checkerboard_color = np.sign(np.random.normal()) # -1(Red) or +1(Green)
target_idx = np.random.randint(0, self.output_dim) # 0(Red-Green) or 1(Green-Red)
# Target cue
input_seq[target_onset:, target_idx] = 1
# Color checkerboard
input_seq[:, self.target_dim:] = np.random.normal(loc=0, size=(self.trial_length, self.color_dim))
input_seq[decision_onset:, self.target_dim:] = np.random.normal(loc=checkerboard_color*coherence,
size=(self.trial_length-decision_onset, self.color_dim))
# Desired output
color_idx = 1 if checkerboard_color > 0 else 0 # (0: Red, 1: Green)
output_direction = 0 if color_idx == target_idx else 1 # (0: Left, 1: Right)
output_seq[decision_onset:, output_direction] = 1
return {'input_seq': input_seq, 'output_seq': output_seq,
'checkerboard_color': checkerboard_color, 'coherence': coherence,
'target_idx': target_idx, 'output_direction': output_direction, 'decision_onset': decision_onset}
위 VisualDiscrimination() 클래스는 인공신경망 학습을 위한 과제 데이터를 랜덤하게 생성시킵니다.
해당 클래스로 객체를 만들고, 인덱싱을 통해 __getitem__() 메서드가 호출되면 여러 시퀀셜 데이터를 딕셔너리 형태로 리턴합니다.
과제가 무척 간단하므로 제가 따로 설명하지 않아도 위 task diagram과 비교하여 코드를 보시면 쉽게 이해가 되실 것이라 생각 됩니다.
특별히 주의 할 점이 있다면 위 코드에서 coherence level은 0부터 100까지 퍼센트로 주어지는 것이 아니라 컬러 체커보드의 색을 샘플링하는 정규 분포의 평균을 변화시키는 가중치 요소로 바꾸어 구현하였습니다.
다시 말해 coherence가 1.0이라고 해도 모든 색이 100% 초록색인 것은 아니며, coherence의 최대값이 1.0인 것도 아니라는 사실을 주의하시기 바랍니다.
다만 coherence의 최소값은 0.0이며 이 경우 모델은 체커보드 패치의 dominant color가 무엇인지 구분 할 수 없습니다.
실제로 이렇게 정의한 VisualDiscrimination() 클래스에 사용되는 task parameter와 task diagram을 그리는 코드는 다음과 같습니다.
import matplotlib.pyplot as plt
from matplotlib import gridspec
task_params = {'target_dim': 2,
'color_dim': 10,
'output_dim': 2,
'target_onset_range': (10, 30),
'decision_onset_range': (50, 80),
'trial_length': 100,
'coherence_range': (0.0, 1.0)}
dataset = VisualDiscrimination(task_params)
data = dataset[0]
input_seq, output_seq = data['input_seq'], data['output_seq']
print(input_seq.shape)
print(output_seq.shape)
fig = plt.figure(figsize=(8,2), dpi=300)
gs = gridspec.GridSpec(2, 1, height_ratios=[12, 2])
axes = [fig.add_subplot(gs[i]) for i in range(2)]
axes[0].imshow(input_seq.T, vmin=-2, vmax=+2, cmap='PiYG')
axes[1].imshow(output_seq.T, cmap='Greys')
color = "Red" if data['checkerboard_color'] == -1 else "Green"
print(f"Coherence: {data['coherence']:2.2f}, Color: {color}, Target: {data['target_idx']}, Output: {data['output_direction']}")
for ax in axes:
ax.set_yticks([])
위 코드를 보시면 과제 시작 후 10-30 time steps 사이에서 타겟의 시각 단서가 주어지고(target_onest_range),
랜덤한 패치의 색이 한쪽으로 결정되는 시점은 50-80 time steps 사이인 것을 확인 할 수 있습니다.
이 경우는 모델이 수행하는 과제이므로 이산화된 해당 time steps은 특정한 현실의 물리적인 시간에 해당하지는 않습니다.
따라서 여러분이은 이렇게 이산화된 time steps의 sampling rate를 조절하여 더 촘촘한 task를 구현 하실 수 있습니다.
높은 sampling rate 하에서 여러분은 모델로부터 반응 시간(reaction time)이나 기타 행동 데이터를 더 정교하게 측정 할 수 있지만,
time steps의 길이가 너무 길어질 경우 모델의 학습 효율이 매우 떨어지며, 모델이 과제 수행에 필요한 과거의 정보를 hidden state에 오래 유지하기 어려울 수 있습니다.
여기까지 여러분은 RNN 모델이 수행 할 수 있는 시각 판별 과제를 구현해 보았습니다. 이제 직접 RNN 모델을 구현하고, 학습시켜 보도록 하겠습니다.
RNN 모델의 구현과 학습
이번 프로젝트에서 RNN 모델은 hidden layer가 하나인 LSTM 기반의 RNN 입니다.
다음 주차 부터는 multi-layer RNN을 구성해 보고, 실제로 해당 layer의 hierarchy를 따라 입력 정보가 출력 정보로 바뀌는 dynamics를 분석 해 볼 것입니다.
이번 주차에서는 과제를 구현하고, RNN 모델을 구현하고, 학습시키고, RNN 모델의 행동 데이터를 분석하는 데에 초점을 맞추었으니 최대한 간단한 형태의 RNN 모델을 만들어 보겠습니다.
import torch.nn as nn
import torch.optim as optim
device = 'cpu'
class RNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(RNN, self).__init__()
self.hidden_dim = hidden_dim
self.lstm_layer = nn.LSTM(input_dim, hidden_dim, batch_first=True)
self.fc_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), self.hidden_dim).to(device)
c0 = torch.zeros(1, x.size(0), self.hidden_dim).to(device)
output, _ = self.lstm_layer(x, (h0, c0))
output = self.fc_layer(output)
return output
이번 프로젝트의 시각 판별 과제는 높은 수준에서 추상화가 되어 있어 많은 계산 자원을 필요로 하지 않습니다.
여러분들이 가진 노트북의 CPU를 활용해도 1~2분이면 충분히 학습이 가능하여 하드웨어를 GPU(cuda)가 아닌 CPU(cpu)로 지정하였습니다.
요즘은 워낙 GPU 기반의 병렬 계산 내지 딥러닝 학습이 보편화 되어 있어 여러분들도 익숙 하실 거라고 생각 하지만,
혹시 익숙하지 않은 분이 있다면 언제 한번 GPU 기반의 고성능 병렬 계산에 대한 튜토리얼을 만들어 보고 싶네요. 😃
이미 LSTM은 잘 알려져 널리 사용되는 순환신경망으로, 이 글을 읽는 대부분이 그 원리와 의의를 잘 알고 계실거라고 생각 합니다.
LSTM layer는 (h, c)로 알려진 두 개의 state를 가지고 있습니다.
h 혹은 hidden state는 기본적인 RNN의 hidden state와 같이 이전 time steps에서 주어진 정보를 현재 혹은 미래로 전달하는데 사용됩니다.
이러한 hidden state는 매 time steps에서 recurrent하게 동작하여 주어진 입력 데이터 시퀀스의 맥락(context)을 추론하는데 사용 됩니다.
반면 c 혹은 cell state는 여러 게이트를 활용하여 hidden state보다 훨씬 더 느리게 업데이트 됩니다.
이를 통해 LSTM 모델은 좀 더 장기적인 기억을 가질 수 있다고 알려져 있습니다.
위 코드에서 입력 데이터 x가 들어온 시점에서 두 state를 0으로 초기화 시켰습니다.
PyTorch가 제공하는 nn.LSTM() 클래스는 입력 데이터 시퀀스의 시간 축을 따라 재귀적으로 동작됩니다.
따라서 우리가 따로 두 state를 업데이트 해 줄 필요는 없으며,
계산된 LSTM layer의 output을 Fully connected layer에 통과시켜 Button response로 변환합니다.
input_dim = task_params['target_dim']+task_params['color_dim']
trial_length = task_params['trial_length']
hidden_dim = 64
output_dim = task_params['output_dim']
batch_size = 128
num_epochs = 2000
learning_rate = 0.001
model = RNN(input_dim, hidden_dim, output_dim).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_history = []
dataset = VisualDiscrimination(task_params)
for epoch in range(num_epochs):
inputs = torch.zeros((batch_size, trial_length, input_dim))
targets = torch.zeros((batch_size, trial_length, output_dim))
for i in range(batch_size):
data = dataset[0]
inputs[i], targets[i] = torch.tensor(data['input_seq']), torch.tensor(data['output_seq'])
inputs.to(device)
targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
loss_history.append(loss.item())
if epoch % 100 == 0:
print (f'Training epoch ({epoch+1}/{num_epochs}), Loss: {loss.item():3.3f}')
모델의 학습은 데이터 배치를 기반으로 동작합니다. 따라서 입력과 출력 데이터 모두 배치 형태로 존재해야 합니다.
매 epoch마다 VisualDiscrimination() 클래스로 생성된 dataset 객체를 이용하여 배치 데이터를 생성시키는 모습입니다.
초기화한 두 데이터 배열의 형태와 차원이 의도한 바와 같은지 늘 확인하세요. 입력 데이터인 inputs의 경우
(batch_size, time_steps, input_dimensions) 형태의 차원을 가지며
출력 데이터인 targets의 경우 (batch_size, time_steps, output_dimensions)을 갖습니다. 각 차원의 위치가 바뀌면 안됩니다.
또 주의하실 점은 위 코드는 dataset 객체를 호출하는(정확히는 호출이 아닙니다만, 함수 호출로 이해하셔도 됩니다) 부분에서 늘 같은 인덱스인 0을 사용 하는 것을 볼 수 있습니다.
우리가 구현한 VisualDiscrimination() 클래스는 인덱스와 무관하게 매번 랜덤한 학습 데이터를 만드므로 같은 인덱스를 쓰셔도 상관이 없습니다.
 Figure 5. RNN 모델의 학습 곡선
Figure 5. RNN 모델의 학습 곡선
Loss function으로는 MSE를 사용하였고, 실제로 위 코드를 돌려 보시면 1분 내외로 학습이 될 것입니다.
사실 인지과제를 수행하는 RNN 모델의 Loss를 정의하고, 학습시키는 데에는 여러 방법이 있습니다.
예전에는 지금 보시는 것 처럼 supervised learning을 통해 계산된 Loss를 바로 역전파하여 학습하는 방법을 널리 사용하였는데요.
저는 개인적으로 Deep reinforcement learning에서 사용하는 reward 기반의 학습 체계가 더 좋다고 생각 합니다.
알려진 여러 model-free learning(A2C, Q-learning)을 이용 할 수 있고,
이 경우에는 모델이 “무엇이, 왜” 틀렸는지 알지 못하고 단지 얼마나 잘했는지(틀렸는지 혹은 맞았는지)만 피드백을 통해 학습하게 됩니다.
나중에 기회가 된다면 reward를 바탕으로 학습되는 강화학습 기반의 RNN 모델도 다루면 좋을 것 같습니다.
RNN 모델의 행동 데이터 분석
이제 여러분은 학습된 모델을 새로운 테스트 데이터에 적용시켜 다양한 행동 데이터를 얻고 분석 할 수 있습니다.
아래 코드에서 with torch.no_grad(): 로 시작하는 컨텍스트 매니저를 이용하여 모델을 테스트 합니다.
해당 컨텍스트 매니저는 신경망 모델의 파라미터들의 그래디언트를 계산하지 않겠다는 선언으로 계산 자원을 아낄 수 있습니다.
여기서 좀 재미있는 부분이 있는데요,
여러분들이 학습시킨 RNN 모델은 사실 버튼을 “애매하게” 누르는 것이 가능하기 때문에(ㅋㅋ) Button_threshold라는 값을 지정하였습니다.
다시 말해 모델의 출력 값이 이 Button_threshold를 넘는 시점에서 모델이 버튼을 “눌렀다”고 생각하는 것으로,
이 시점에서 반응 시간(reaction time)와 정확도(error)를 측정 하도록 하겠습니다.
test_batch_size = 512
Button_threshold = 0.9
dataset = VisualDiscrimination(task_params)
with torch.no_grad():
inputs = torch.zeros((test_batch_size, trial_length, input_dim))
targets = torch.zeros((test_batch_size, trial_length, output_dim))
coherence = np.zeros(test_batch_size)
color = np.zeros(test_batch_size)
desired_direction = np.zeros(test_batch_size)
decision_onset = np.zeros(test_batch_size)
for i in range(test_batch_size):
data = dataset[0]
inputs[i], targets[i] = torch.tensor(data['input_seq']), torch.tensor(data['output_seq'])
color[i], coherence[i] = data['checkerboard_color'], data['coherence']
desired_direction[i], decision_onset[i] = data['output_direction'], data['decision_onset']
inputs.to(device)
outputs = model(inputs)
outputs = outputs.cpu().numpy()
targets = targets.cpu().numpy()
RT = np.full((test_batch_size), np.nan)
error = np.ones(test_batch_size)
for i in range(test_batch_size):
for t in range(trial_length):
if np.max(outputs[i,t,:], axis=-1) > Button_threshold:
RT[i] = t - decision_onset[i]
response = np.argmax(outputs[i,t,:], axis=-1)
if desired_direction[i] == response and RT[i] >= 0:
error[i] = 0
break
RNN 모델의 Button response를 보면 다음과 같습니다. 제시된 시각 자극의 coherence가 부족하여 과제에서 요구되는 response 하는 데에 필요한 evidence가 부족한 경우
모델은 느리고, 애매한 response를 보이는 것을 확인 할 수 있습니다.
 Figure 6. RNN 모델의 Button response
Figure 6. RNN 모델의 Button response
제시되는 체커보드 패치의 coherence에 따른 반응 시간(reaction time) 결과를 Chandrasekaran et al. (2017) 연구에서 제시된 짧은 꼬리 원숭이의 행동 데이터와 비교해 보았습니다.
굉장히 재미있게도 원숭이의 행동 데이터와 RNN 모델 사이에서 유사한 패턴을 볼 수 있었는데요.
다시 말해 잘 훈련된 RNN 모델도 주어지는 시각 자극에 따라 응답의 속도가 바뀐다는 점을 시사합니다.
여기선 응답 속도라는 말 보다는 응답을 하기 위해 필요한 time step의 수 라고 표현하는 것이 정확하겠습니다.
 Figure 7. 짧은 꼬리 원숭이와 RNN 모델의 행동 데이터 비교
Figure 7. 짧은 꼬리 원숭이와 RNN 모델의 행동 데이터 비교
마치며
여기까지 정말 고생 많으셨습니다. 이번 주차의 주제는 재미있으셨나요?
제가 글을 쓰고, 정리하는 속도가 느려서 늘 약속드린 날 보다 늦게 공지하게 되네요.
오프라인 강의를 하는 것이 더 시간이 덜 드는데, 나중에 다른 사람도 볼 수 있게 학습 자료를 정리하는 것이 참 시간이 오래 걸리는 일 같습니다.
이 정도를 준비하는데에도 시간이 이렇게 걸리는데… 그러면서도 원하는 만큼 충분히 설명하지 못한 부분이 많아서 아쉽네요. 넓은 마음으로 양해 부탁드립니다.
이번 주차는 따로 과제나 도전 문제가 없습니다. 다만 희망하시는 분들을 대상으로 인지과제 모델링과 RNN의 state dynamics 분석에 대해서 오프라인 피드백을 진행 할 예정입니다.
희망하시는 분들은 2023년 2월 19일 23:59까지 구현하고자 하는 인지과제에 대해 PPT 5장 분량의 프로포절을 제출해 주시면 됩니다.
그 다음날인 20일 오후 2시에 제출해 주신 모든 분들이 함께 모여 오프라인 미팅을 갖고, 각자의 과제에 대해 발표하는 시간을 갖도록 하겠습니다.
제출하신 프로포절은 과제의 적절한 추상화 수준과 구현 방법에 대한 디테일이 포함되어 있어야 합니다. 이에 근거하여 이번 주차의 점수와 피드백을 드리도록 하겠습니다. 감사합니다.
Recommended reading
- Chandrasekaran, C., Peixoto, D., Newsome, W. T. & Shenoy, K. V. Laminar differences in decision-related neural activity in dorsal premotor cortex. Nat Commun 8, 614 (2017).
- Yang, G. R. & Wang, X.-J. Artificial Neural Networks for Neuroscientists: A Primer. Neuron 107, 1048–1070 (2020).
- Yang, G. R., Joglekar, M. R., Song, H. F., Newsome, W. T. & Wang, X.-J. Task representations in neural networks trained to perform many cognitive tasks. Nat Neurosci 22, 297–306 (2019).
- Lu, Q., Hasson, U. & Norman, K. A. A neural network model of when to retrieve and encode episodic memories. Elife 11, (2022).
PsychRNN: https://github.com/murraylab/PsychRNNPsyNeuLink: http://www.psyneuln.deptcpanel.princeton.edu